
Structuring the Shoreline: Using AI to Decode Zoning for Coastal Resilience
By: Paige Casebere


Project Contexts and Goals
Coastal cities are running out of time. Rising sea levels, storm surges, and shoreline erosion are becoming harder to ignore. In response, many municipalities are relying on shoreline armoring infrastructure like seawalls, revetments, and bulkheads to protect property and infrastructure. But the policies that govern these responses are buried deep in complex zoning ordinances.
The problem:
Zoning codes are long, inconsistent, and spread across hundreds of municipal websites. Each city structures their ordinances differently, and the language used to describe armoring is vague or highly technical. Urban planners trying to find clear information, like how far structures must be set back from the shore, or whether armoring is even allowed often spend hours manually combing through documents.
This project is about making that information easier to access.
I’m building a tool that uses natural language processing (NLP) to extract shoreline-related regulations from zoning documents. By identifying and pulling key terms like setback, revetment, or permit approval the tool can turn unstructured legal text into a searchable dataset.
Why this matters:
Right now, there’s no fast way to compare shoreline regulations across cities. But understanding how different places manage armoring is critical for planners trying to write smarter, more climate-responsive policies. If we can surface and structure this information using AI, it could help planners:
Learn from other jurisdictions
Spot policy gaps or contradictions
Make informed updates to their own codes
What inspired this:
I built this project off of a report from Michigan Sea Grant, where researchers manually reviewed dozens of shoreline ordinances across the state. That work proved it’s possible, but also showed how slow and resource-intensive the process can be. I wanted to explore how much of that work could be automated without losing the nuance.
The goal: Extract and organize shoreline armoring policies using AI, Make zoning data easier to compare, visualize, and understand, Help planners make faster, better decisions for climate resilience
Methods
To extract shoreline armoring policies from zoning codes, I used a mix of manual collection and natural language processing (NLP) techniques. The idea was to take scattered legal text from different cities and organize it into a clean, structured format something planners could actually use.
Step 1: Document Collection
I sourced zoning ordinances from cities using platforms like Municode, eCode360, and official city planning websites. I focused on coastal cities that are actively managing erosion or have visible shoreline infrastructure. Most of the documents were long-form HTML or PDFs.
Step 2: Identifying What to Extract
Using the Michigan Sea Grant’s report on shoreline ordinances as a guide, I narrowed the focus to a few key regulatory variables:
Whether shoreline armoring is allowed or prohibited
Setback distances from the waterline
Materials permitted or banned (e.g. concrete, natural rock)
Permit requirements and approval processes
Mentions of “natural shoreline” or preservation goals
Step 3: Text Extraction and Processing
I used Python along with:
BeautifulSoup to scrape zoning pages
Regex to locate patterns like measurement distances or permit clauses
spaCy to perform Named Entity Recognition (NER) and highlight entities like agency names, ordinance sections, or permit authorities
Pandas to store the results in a structured table
The goal wasn’t just keyword search—it was pulling the full context around each term. For example, not just spotting the word “revetment,” but understanding whether it’s allowed or restricted, and under what conditions.
Step 4: Data Structuring and Visualization
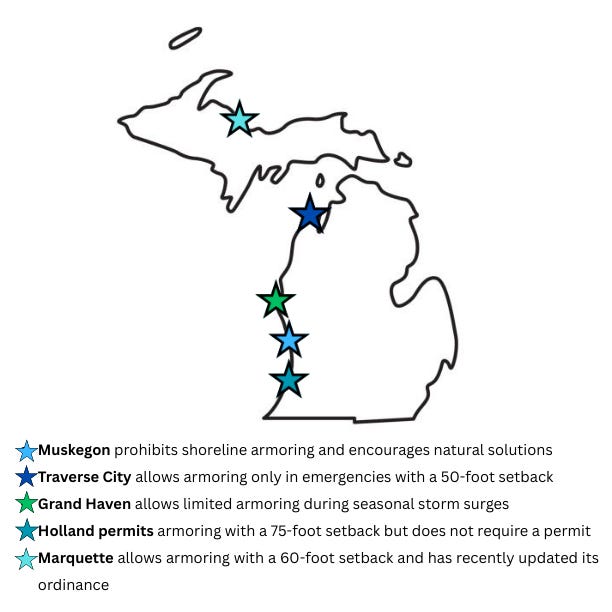
Once extracted, I cleaned the data and organized it into a spreadsheet to compare how different cities regulate armoring. I then created simple visualizations to show variation across jurisdictions—for example, which cities explicitly ban hard shoreline structures, or how far back structures must be built from the water.
Outcomes: What This Tool Produces
The tool I built uses natural language processing (NLP) to extract and organize zoning information related to shoreline armoring a method cities use to protect coastlines from erosion.
Instead of planners having to comb through dozens of pages of dense legal text, this tool turns messy, unstructured content into a clean, structured dataset that makes patterns easier to see and decisions easier to make.
What the Code Extracts:
Using a combination of spaCy (for Named Entity Recognition), regex, and Pandas, I pulled out variables that are critical for coastal planning:
City name
Whether armoring is allowed
Required setback distance from the shoreline
Whether a permit is required
Shoreline type (e.g., Lake Michigan, Lake Superior)
Additional notes or legal restrictions
This data can be used to compare policies between cities and spot inconsistencies or missing information at a glance.
What the Output Looks Like
Each row in the dataset represents a Michigan city. Each column is a zoning rule. Together, they give a side-by-side view of how shoreline protection policies differ across jurisdictions.
Here a sample output….
Final Dataset Download
The output is saved as a CSV and can be opened in Excel, Google Sheets, or imported into any data tool.
Try It Yourself
Here’s a code snippet that shows how to load and explore the dataset:
import pandas as pd
# Load the shoreline zoning dataset
df = pd.read_csv("shoreline_data_final.csv")
# Preview the first few rows
df.head()
🔗Open my full Colab notebookWhat This Enables for Planners
If scaled up, this prototype could process zoning documents from dozens or hundreds of cities. With structured data, planners can:
Compare permit and setback rules side-by-side
Filter policies by shoreline type or region
Identify inconsistencies or policy gaps
Build dashboards or tools to visualize coastal risk data
The goal isn’t to replace expert judgment just to streamline the grunt work so cities can respond smarter and faster to coastal threats.
Reflections: What I Took Away from This Project
Zoning docs are not made for humans
Reading through even a handful of shoreline ordinances, I realized how dense, inconsistent, and hard to navigate these documents really are. Some cities buried key policies in 40+ pages of legal jargon, while others barely mentioned armoring at all.
This made it clear why planners need better tools not to automate their decisions, but to give them a faster way to sort through the mess.
AI didn’t replace thinking…it made my work faster
One thing I learned fast: NLP models like spaCy are helpful, but only if you already know what you’re looking for. I had to bring in my Urban Tech background to:
Decide which rules mattered (e.g. setbacks, permits, shoreline types)
Design the structure of my dataset based on real planning needs
Spot and fix extraction errors the model made (especially with vague or incomplete phrasing)
So the AI made it faster, but I still had to guide the logic and know the context. That made it feel like a real collaboration between human knowledge and machine efficiency..
I finally saw AI working for cities
This was one of the first times I felt like I used AI for planners, not just to show off code. It helped organize real legal language into something clear, structured, and visual. That shift from text to usable data was the most rewarding part. This project showed me that AI could: help standardize and compare local policies, make regulatory text accessible to non-experts, and speed up planning workflows without replacing judgment
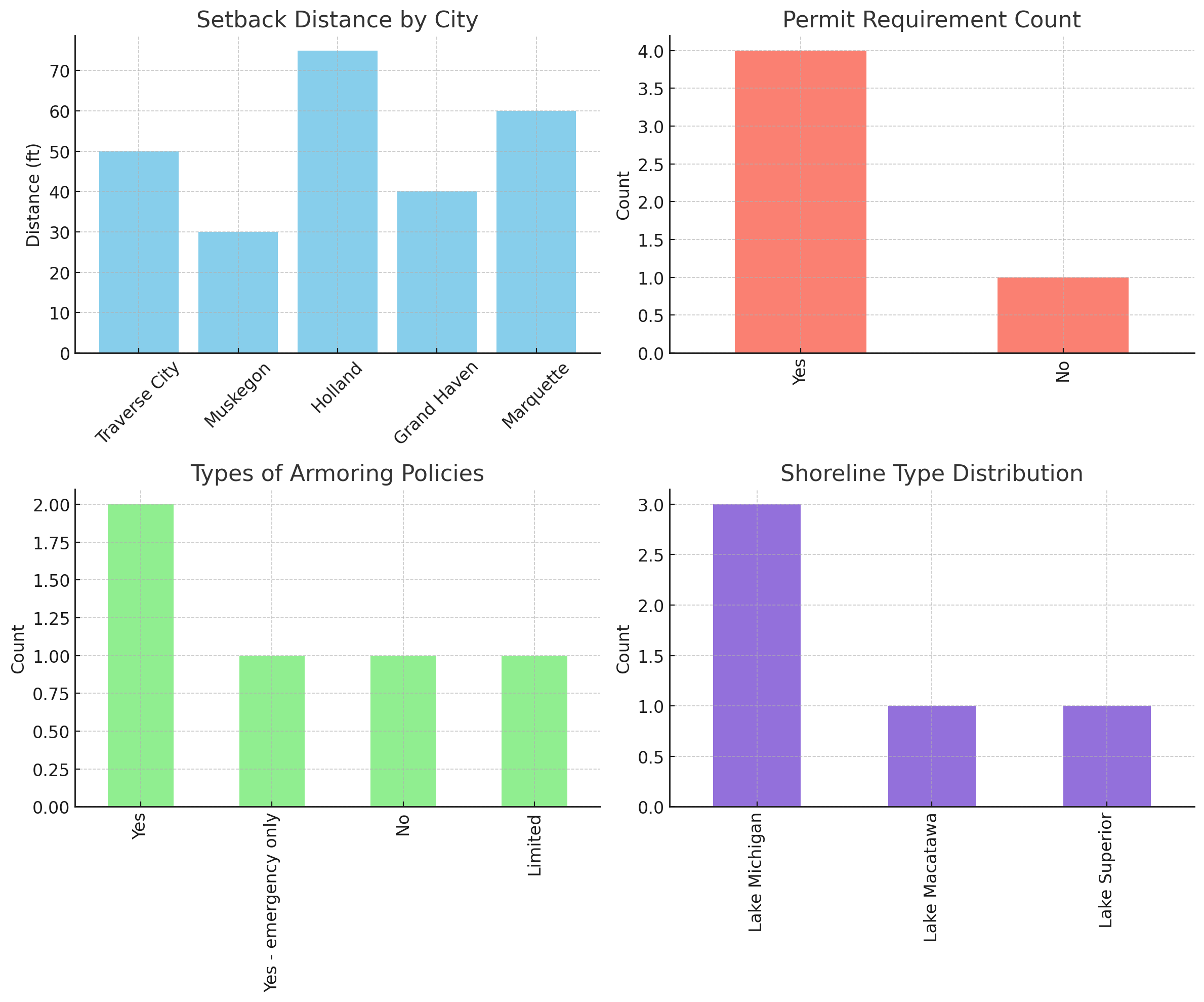
Visualization made it click
Once I had the data structured, I visualized things like:
Which cities allowed shoreline armoring (and under what conditions)
Average setback distances
Permit requirements
Shoreline type by city
Seeing those bar graphs and distributions helped me spot trends, gaps, and outliers instantly. It also made it way easier to explain the results to someone else, which is key for public-facing planning work.
Where I want to take this
I could definitely see this expanding to analyze building codes, sustainability regulations, or even housing policies. Basically anything that’s written in a long document and used in local decision-making. With the right filters and AI support, it can be made 10x easier to understand.
Appendix & References
Instructor:
Prof. Xiaofan Liang, Urban AI – University of Michigan
Google Drive: Project Folder
References & Source Materials
Michigan Sea Grant – Coastal Shoreline Ordinances Report
Local Government Approaches to Shoreline Protection in Michigan
https://www.michiganseagrant.org/coastal-resilience-resource-hub/resources/policy/coastal-shoreline-ordinances/Urban Institute – Automating Zoning Data Collection with NLP
Challenges and Lessons Learned from Using AI to Analyze Planning Documents
https://www.urban.org/sites/default/files/2023-02/Automating%20Zoning%20Data%20Collection.pdfGreen, B. (2022). "The Contestation of AI Ethics."
(Relevant to planning and AI governance frameworks)
https://arxiv.org/abs/2201.03208American Planning Association – "Smart Cities and AI in Planning"
https://www.planning.org/publications/document/9204267/National Oceanic and Atmospheric Administration (NOAA)
Coastal Resilience and Shoreline Erosion Trends
https://coast.noaa.gov/states/fast-facts/shoreline-change.htmlCode for America – “AI and Local Government”
Guidance for Responsible Use of AI Tools in Civic Tech
https://www.codeforamerica.org/news/ai-in-local-government/ICLEI – Local Governments for Sustainability
Resilient Cities and Adaptation Planning Resources
https://iclei.org/en/Resilient_Cities.htmlCity Zoning Ordinances Used in Dataset
Traverse City, MI – https://library.municode.com/mi/traverse_city
Muskegon, MI – https://ecode360.com/MU4102
Holland, MI – https://library.municode.com/mi/holland
Grand Haven, MI – https://ecode360.com/GR4234
Marquette, MI – https://ecode360.com/MA1695
Tools & Libraries Used
Python
Pandas – Data wrangling and CSV output
spaCy – Named Entity Recognition (NER)
BeautifulSoup – Web scraping and HTML parsing
Regex (re) – Text pattern detection
Matplotlib – Data visualization and graphs
Google Colab – Cloud-based notebook execution
Google Sheets – CSV formatting and manual inspection
Substack – Final presentation and public-facing write-up